https://www.oreilly.com/library/view/head-first-data/9780596806224/ch01.html
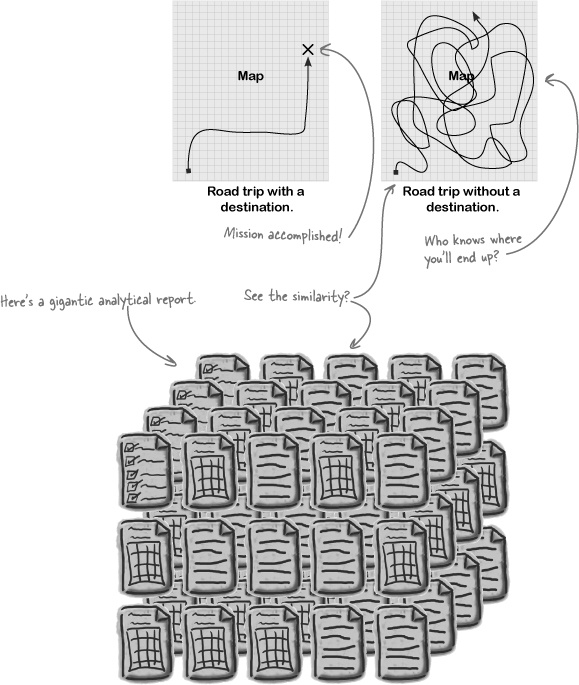
Seek patterns in the data. If you have already begun coding just stop whatever you are doing and read this text. Imagine that you have a map and you want to head a location, first you need to check what path you need to take before heading.
You might think that "I see a bunch of words that don't make sense to me". Just looking at the data itself is not enough to come up with the problems and solutions. The observation phase is all about identifying problems. Let us give you an insight: when you look at the development data, can you see a pattern between the input data and the oracle data? This stage is also called exploratory data analysis. It is a life-saving skill. It will guide you to generate hypotheses that are worthwhile to test.
Generate hypotheses that would explain the pattern. After the previous step you probably have some ideas about what a possible hypothesis might be. In this assignment, your model choices are limited to feedforward neural networks and k nearest neighbors classifiers.
Now you need to hypothesize your own models. You have many options. Generate multiple competing hypotheses; don't just settle for the first option you think of. Some of them might be a good fit to your problem based on your observations. Some of them might not.
Compare and contrast the hypotheses analytically. Now that you have generated a bunch of alternative competing hypotheses, you need to contrast them and discuss their plausibility before testing them. You are already familiar with the terms language bias and search bias. Explain your hypotheses in terms of:
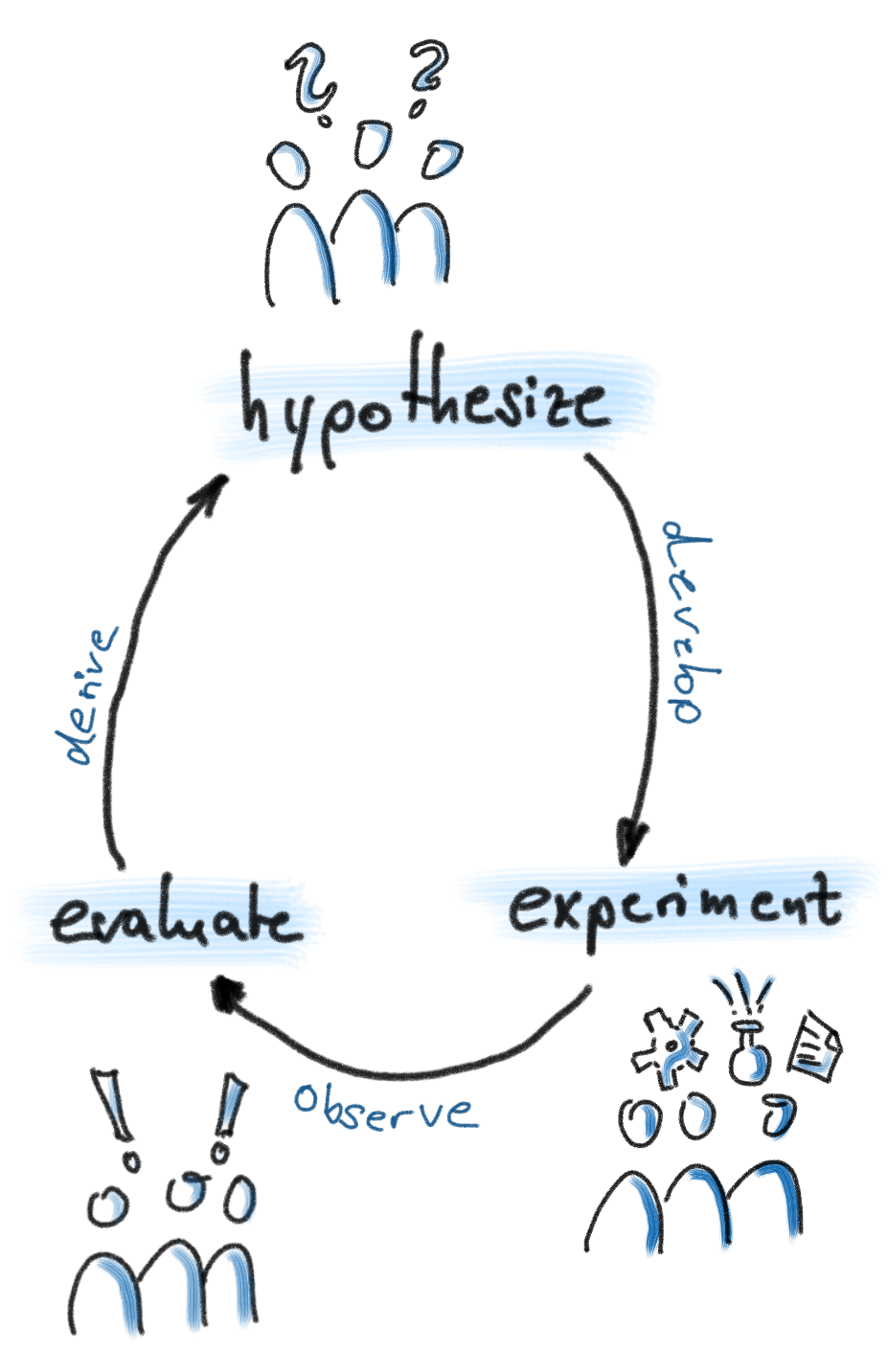
Compare and contrast the hypotheses experimentally.
Do error analysis on the experimental results. What patterns did your hypotheses fail to capture? Why not?
Repeat the scientific method cycle. You have finished one iteration of scientific method. Return to step 2, and generate new hypotheses.
You need to complete this assignment on CSE Lab2 machines. You don't necessarily need to go to the physical lab in person (although you could). CSE Lab2 has 54 machines, which you can remotely log into with your CSE account. Their hostnames range from csl2wk00.cse.ust.hk to csl2wk53.cse.ust.hk. Create your project under your home directory which is shared among all the CSE Lab2 machines.
For non-CSE students, visit the following link to create your CSE account. https://password.cse.ust.hk:8443/pass.html
In the registration form, there are three "Set the password of" checkboxes. Please check the second and the third checkboxes.
Your home directory in CSE Lab2 has only 100MB disk quota. To see a report of the disk usage in your home directory, you can run du command. It is recommended that you have at least 30MB available before you start this assignment.
Do not delete your assignment 2. You will need them.
Please download the starting pack (version 4) tarball, and extract it to your home directory on CSE Lab2 machine. This starting pack contains the skeleton code, the feedforward network library and the dataset. The starting pack has the following structure:
COMP4221_2019Q1_a3/ ├── include/* ├── lib/* ├── part_review/ │ ├── assignment.cpp (your code goes here) │ ├── model.xml (your trained POS tagger goes here) | ├── assignment.hpp │ ├── main.cpp │ ├── util.hpp │ └── makefile ├── part_a/ │ ├── report.xlsx (your report goes here) │ ├── assignment.cpp (your code goes here) │ ├── assignment.hpp │ ├── main.cpp │ ├── util.hpp │ └── makefile ├── part_b/ │ ├── report.xlsx (your report goes here) │ ├── assignment.cpp (your code goes here) │ ├── model.xml (your trained chunker goes here) │ ├── assignment.hpp │ ├── main.cpp │ ├── util.hpp │ └── makefile └── part_c/ ├── report.xlsx (your report goes here) ├── assignment.cpp (your code goes here) ├── assignment.hpp ├── main.cpp ├── util.hpp └── makefile
The only two files you need to touch are report.xlsx and assignment.cpp in part_review, part_a part_b and part_c directories. You do need to submit model.xml, but those are generated by our main program.
After downloading the starting pack, you can run tar -xzvf COMP4221_2019Q1_a3.tgz to extract the starting pack
After you extract the starting pack, go into its part_review directory and run make and main. You should see something similar like this:
csl2wk14:yyanaa:355> make g++8 -std=c++17 -I../include -c -o assignment.o assignment.cpp g++8 -std=c++17 -I../include -o main main.cpp assignment.o -L../lib -lmake_transducer csl2wk14:yyanaa:356> main training data size:32962 training development testing accuracy: 0.758855 prediction saved to predict.xml model saved to model.xml
The evaluation method of this assignment follows CoNLL 2000 shared task (text chunking) and CoNLL 2009 shared task (semantic role labeling). And test script forked from this repository.
To perform this assignment, you need a POS tagger. Luckily, you have created one in assignment 2. Of course this starting pack does not contain your POS tagger model. You need to copy the code from your assignment 2, and bring it to part_review/assignment.cpp. Note that you cannot simply overwrite this part_review/assignment.cpp with the corresponding file in your assignment 2. This is because, this assignment 3 has many parts, and to void naming conflict, your code should be correctly namespaced. In the starting code, you can see something like this:
#include "assignment.hpp"
using namespace tg;
namespace part_review {
const unsigned NUM_EPOCHS = 5;
transducer_t your_classifier(const vector<token_t> &vocab, const vector<postag_t> &postags) {
// classifier topology goes here ...
}
vector<token_t> get_features(const vector<token_t> &sentence, unsigned token_index) {
// feature extraction goes here ...
}
}
Make sure that when bringing your code from assignment 2, all functions are defined in the part_review namespace.
The dataset files are in almost the same format as it is in assignment 2 (but changed the attribute name for POS tag from value to type, so that it's more consistent with this assignment). Here are their links: traindata_postag.xml and testdata_postag.xml.
You can run make and main to train and test your POS tagger. Your POS tagger will be automatically saved to part_review/model.xml. You might notice that the reported accuracy is lower than what you expected. This is because, your POS tagger is not trained on the full vocabulary of the dataset anymore. It is trained on the vocabulary that contains top 1000 most frequent tokens, while all other tokens are treated as unknown. There are a few reasons for this:
Chunking is the task to group tokens into chunks in such a way that related words become member of the same chunks. For example, consider the following sentence:
He reckons the current account deficit will narrow to only # 1.8 billion in September .
A natural way of chunking will be: (chunks represented with an upper bar)
__ _______ ___________________________ ___________ __ __________________ __ _________ He reckons the current account deficit will narrow to only # 1.8 billion in September .
IOBES is a common tagging format for chunk tagging. It reduces a chunking problem into a classification problem, by introducing the following tags:
In this way, the previous chunking can be tagged as: (tags are below each token)
__ _______ ___________________________ ___________ __ __________________ __ _________ He reckons the current account deficit will narrow to only # 1.8 billion in September . S S B I I E B E S B I I E S S O
In this assignment, you will implement a model that performs chunking by predicting IOBES tags
The first step in scientific research is to observe the data. You are provided with a traindata_part_a.xml and a devdata_part_a.xml. They represent the training set and the development test set respectively.
Both training set and development set are in XML format, in which:
Here is an example:
<?xml version="1.0" encoding="UTF-8" ?>
<dataset>
<sent>
<chunk>
<token>He</token>
</chunk>
<chunk>
<token>reckons</token>
</chunk>
<chunk>
<token>the</token>
<token>current</token>
<token>account</token>
<token>deficit</token>
</chunk>
<chunk>
<token>will</token>
<token>narrow</token>
</chunk>
<chunk>
<token>to</token>
</chunk>
<chunk>
<token>only</token>
<token>#</token>
<token>1.8</token>
<token>billion</token>
</chunk>
<chunk>
<token>in</token>
</chunk>
<chunk>
<token>September</token>
</chunk>
<token>.</token>
</sent>
</dataset>
As you can see, the data in not given in IOBES format. You need to process the data into IOBES format. To make your life easier, we have already converted the dataset into IOBES format with this provided converter function string syntactic_chunks_to_iobes(const string &syntactic_chunk_xml);. traindata_part_a_iobes.xml and devdata_part_a_iobes.xml are the converted datasets, in which:
An example of such data is as follows:
<?xml version="1.0" encoding="UTF-8" ?>
<dataset>
<sent>
<token type="S">He</token>
<token type="S">reckons</token>
<token type="B">the</token>
<token type="I">current</token>
<token type="I">account</token>
<token type="E">deficit</token>
<token type="B">will</token>
<token type="E">narrow</token>
<token type="S">to</token>
<token type="B">only</token>
<token type="I">#</token>
<token type="I">1.8</token>
<token type="E">billion</token>
<token type="S">in</token>
<token type="S">September</token>
<token type="O">.</token>
</sent>
</dataset>
Find insightful patterns in the data. Good observations comes from statistical analysis. For example, here are some directions may be useful in finding patterns.
Report your observations about the data. You might use the hints we gave you but you are not limited to them.
According to the pattern you observed, please propose some IOBES tagging models. The next step is to compare those models theoretically, in the following aspects:
Write down your proposed hypotheses together with their pros and cons based on questions above.
Here you need to design experiments that validate/invalidate the hypotheses you came up with.
Write a detailed explanation for your each model indicating how are they reflecting their underlying hypothesis
Write your own C++ code to define your model.
Build a feedforward network that reflects your hypothesis. The starting pack already contains a fully functioning 2-layer feedforward network as an example:
/**
* create your custom classifier by combining transducers
* the input to your classifier will a list of tokens
* when creating your custom classifier, the training set is passed as a parameter
* this is because you need to assemble your vocabulary from training set
* \param training_set the training set that your classifier will train on
* \param postags the list of all POS tags.
* \param iobes_tags the list of IOBES tags. it contains "I" "O" "B" "E" "S" (but not necessarily in order)
* \return
*/
transducer_t your_classifier(const vector<sentence_t> &training_set, const vector<symbol_t> &postags,
const vector<symbol_t> &iobes_tags) {
// in this starting code, we demonstrates how to construct a 2-layer feedforward neural network
// that takes the target token and the POS tag of the target token as input
// first you need to assemble the vocab you need
// in this simple model, the vocab is the top 1000 most frequent tokens in training set
// we provide a frequent_token_collector utility,
// that can count token frequencies and collect the top X most frequent tokens
// all out-of-vocabulary tokens will be treated as "unknown token"
frequent_token_collector vocab_collector;
for (const auto &sentence:training_set) {
for (const auto &token:sentence) {
vocab_collector.add_occurence(token);
}
}
vector<symbol_t> vocab = vocab_collector.list_frequent_tokens(1000);
// create an embedding lookup layer for token input
auto embedding_lookup = make_embedding_lookup(64, vocab);
// the size of postag vocabulary are small, a onehot layer will work just fine
auto postag_onehot = make_onehot(postags);
auto concatenate = make_concatenate(2);
auto dense0 = make_dense_feedfwd(64, make_tanh());
auto dense1 = make_dense_feedfwd(iobes_tags.size(), make_softmax());
auto onehot_inverse = make_onehot_inverse(iobes_tags);
return compose(group(embedding_lookup, postag_onehot), concatenate, dense0, dense1, onehot_inverse);
}
The starting pack also contains an example on how to supply the target token together the target token's POS tag as context:
/**
* besides the target token to chunk, your model may also need other "context" input
* this function defines the inputs that your model expects
* \param sentence the sentence where the token is in
* \param postags the POS tags of the sentence (predicted by your model)
* \param target_index the position of the target token to chunk
* \return
*/
vector<feature_t>
get_features(const vector<symbol_t> &sentence, const vector<symbol_t> &postags, unsigned target_index) {
// TODO: define what input to feed to your classifier
// this starting code demonstrates how to define input as:
// the target token, the target token's POS tag
return vector<feature_t>{sentence[target_index], postags[target_index]};
}
After you have built one of your proposed models in assignment.cpp, you can run the command make and ./main to compile and run your model. You will get a part_a_prediction.xml, which contains your model prediction on the development test dataset, in exactly the same format as all other data files. Please observe your model output, find out which tokens your model failed to tag, and most importantly, explain why.
Besides outputting the part_a_prediction.xml, you will also get a F score of your model. The F score combines the precision (the percentage of detected chunks that are correct) and the recall (the percentage of phrases in the data that were found by the chunker) in such a way:
Where P means precision and R means recall.
When calculating precision and recall, in case your model prediction is not self consistent, they are resolved according to the following rules:
For example, B I B E E, will be converted into B E B E S
Write down your model F score in the report.
Find out which test examples your model failed to classify, and why your model failed to classify them. If there are more than 4 failures, you only need to report 4.
After analyzing why your model went wrong, you should be able to make a better hypothesis. Now you have completed one iteration of scientific research. On the next iteration, you compare your new hypothesis theoretically and empirically again, doing more error analysis, and coming up with more awesome model.
Start another scientific method iteration.
May 1 23:59
You need to submit the following tgz archives via CASS:
Shallow syntactic parsing is the task to group tokens into chunks in such a way that syntactically related words become member of the same chunks, in addition, each chunk should have a syntactic tag. For example, consider the following sentence:
He reckons the current account deficit will narrow to only # 1.8 billion in September .
A shallow syntactic parse will be:
NP VP NP VP PP NP PP NP He reckons the current account deficit will narrow to only # 1.8 billion in September .
IOBES format can also be applied to typed chunking. It reduces a typed chunking problem into a classification problem, by introducing tags prefixes (assuming the chunk type is X):
In this way, the previous chunking can be tagged as: (tags are below each token)
NP VP NP VP PP NP PP NP He reckons the current account deficit will narrow to only # 1.8 billion in September . S-NP S-VB B-NP I-NP I-NP E-NP B-VP E-NP S-PP B-NP I-NP I-NP E-NP S-PP S-NP O
In this assignment, you will implement a model that performs shallow syntactic parsing by predicting IOBES tags
The first step in scientific research is to observe the data. You are provided with a traindata.xml and a devdata.xml. They represent the training set and the development test set respectively.
Both training set and development set are in XML format, in which:
Here is an example:
<?xml version="1.0" encoding="UTF-8" ?>
<dataset>
<sent>
<chunk type="NP">
<token>He</token>
</chunk>
<chunk type="VP">
<token>reckons</token>
</chunk>
<chunk type="NP">
<token>the</token>
<token>current</token>
<token>account</token>
<token>deficit</token>
</chunk>
<chunk type="VP">
<token>will</token>
<token>narrow</token>
</chunk>
<chunk type="PP">
<token>to</token>
</chunk>
<chunk type="NP">
<token>only</token>
<token>#</token>
<token>1.8</token>
<token>billion</token>
</chunk>
<chunk type="PP">
<token>in</token>
</chunk>
<chunk type="NP">
<token>September</token>
</chunk>
<token>.</token>
</sent>
</dataset>
As you can see, the data in not given in IOBES format. To make your life easier, we have already converted the dataset into IOBES format with this provided converter function string syntactic_chunks_to_iobes(const string &syntactic_chunk_xml);. devdata_part_b_iobes.xml and devdata_part_b_iobes.xml are the converted datasets, in which:
An example of such data is as follows:
<?xml version="1.0" encoding="UTF-8" ?>
<dataset>
<sent>
<token type="S-NP">He</token>
<token type="S-VP">reckons</token>
<token type="B-NP">the</token>
<token type="I-NP">current</token>
<token type="I-NP">account</token>
<token type="E-NP">deficit</token>
<token type="B-VP">will</token>
<token type="E-VP">narrow</token>
<token type="S-PP">to</token>
<token type="B-NP">only</token>
<token type="I-NP">#</token>
<token type="I-NP">1.8</token>
<token type="E-NP">billion</token>
<token type="S-PP">in</token>
<token type="S-NP">September</token>
<token type="O">.</token>
</sent>
</dataset>
Find insightful patterns in the data. Good observations comes from statistical analysis. For example, here are some directions may be useful in finding patterns.
Report your observations about the data. You might use the hints we gave you but you are not limited to them.
According to the pattern you observed, please propose some shallow syntactic parsing models. The next step is to compare those models theoretically, in the following aspects:
Write down your proposed hypotheses together with their pros and cons based on questions above.
Here you need to design experiments that validate/invalidate the hypotheses you came up with.
Write a detailed explanation for your each model indicating how are they reflecting their underlying hypothesis
Write your own C++ code to define your model.
Build a feedforward network that reflects your hypothesis. The starting pack already contains a fully functioning 2-layer feedforward network as an example:
/**
* create your custom classifier by combining transducers
* the input to your classifier will a list of tokens
* when creating your custom classifier, the training set is passed as a parameter
* this is because you need to assemble your vocabulary from training set
* \param training_set the training set that your classifier will train on
* \param postags the list of all POS tags.
* \param iobes_tags the list of IOBES tags. it contains "I" "O" "B" "E" "S" (but not necessarily in order)
* \return
*/
transducer_t your_classifier(const vector<sentence_t> &training_set, const vector<symbol_t> &postags,
const vector<symbol_t> &iobes_tags) {
// in this starting code, we demonstrates how to construct a 2-layer feedforward neural network
// that takes the target token and the POS tag of the target token as input
// first you need to assemble the vocab you need
// in this simple model, the vocab is the top 1000 most frequent tokens in training set
// we provide a frequent_token_collector utility,
// that can count token frequencies and collect the top X most frequent tokens
// all out-of-vocabulary tokens will be treated as "unknown token"
frequent_token_collector vocab_collector;
for (const auto &sentence:training_set) {
for (const auto &token:sentence) {
vocab_collector.add_occurence(token);
}
}
vector<symbol_t> vocab = vocab_collector.list_frequent_tokens(1000);
// create an embedding lookup layer for token input
auto embedding_lookup = make_embedding_lookup(64, vocab);
// the size of postag vocabulary are small, a onehot layer will work just fine
auto postag_onehot = make_onehot(postags);
auto concatenate = make_concatenate(2);
auto dense0 = make_dense_feedfwd(64, make_tanh());
auto dense1 = make_dense_feedfwd(iobes_tags.size(), make_softmax());
auto onehot_inverse = make_onehot_inverse(iobes_tags);
return compose(group(embedding_lookup, postag_onehot), concatenate, dense0, dense1, onehot_inverse);
}
The starting pack also contains an example on how to supply the target token together the target token's POS tag as context:
/**
* besides the target token to chunk, your model may also need other "context" input
* this function defines the inputs that your model expects
* \param sentence the sentence where the token is in
* \param postags the POS tags of the sentence (predicted by your model)
* \param target_index the position of the target token to chunk
* \return
*/
vector<feature_t>
get_features(const vector<symbol_t> &sentence, const vector<symbol_t> &postags, unsigned target_index) {
// TODO: define what input to feed to your classifier
// this starting code demonstrates how to define input as:
// the target token, the target token's POS tag
return vector<feature_t>{sentence[target_index], postags[target_index]};
}
After you have built one of your proposed models in assignment.cpp, you can run the command make and ./main to compile and run your model. You will get a part_b_prediction.xml, which contains your model prediction on the development test dataset, in exactly the same format as all other data files. Please observe your model output, find out which tokens your model failed to tag, and most importantly, explain why.
Besides outputting the part_b_prediction.xml, you will also get a F score of your model. The F score combines the precision (the percentage of detected chunks that are correct) and the recall (the percentage of phrases in the data that were found by the chunker) in such a way:
Where P means precision and R means recall.
When calculating precision and recall, in case your model prediction is not self consistent, they are resolved according to the following rules:
For example, B-NP I-NP I-VP I-PP E-VP, will be converted into B-NP E-NP S-VP S-PP S-VP
Write down your model F score in the report.
Find out which test examples your model failed to classify, and why your model failed to classify them. If there are more than 4 failures, you only need to report 4.
After analyzing why your model went wrong, you should be able to make a better hypothesis. Now you have completed one iteration of scientific research. On the next iteration, you compare your new hypothesis theoretically and empirically again, doing more error analysis, and coming up with more awesome model.
Start another scientific method iteration.
May 10, 23:59
You need to submit assignment3_part_b.tgz archives via CASS, that only contains:
Note: If you want to update your POS tagger model that you built in review part, you can re-submit to the part A checkpoint.
Shallow semantic parsing (or semantic role labeling) is the task to group tokens into chunks indicating their semantic roles. For example, consider the following sentence:
He reckons the current account deficit will narrow to only # 1.8 billion in September .
A shallow semantic parse will be:

IOBES format can also be applied to typed chunking. It reduces a typed chunking problem into a classification problem, by introducing tags prefixes (assuming the chunk type is X):
In this way, the previous chunking can be tagged as: (tags are below each token)
He reckons the current account deficit will narrow to only # 1.8 billion in September . S-who S-did-what B-to-whom I-to-whom I-to-whom I-to-whom I-to-whom I-to-whom I-to-whom I-to-whom I-to-whom I-to-whom I-to-whom I-to-whom E-to-whom O He reckons the current account deficit will narrow to only # 1.8 billion in September . O O B-who I-who I-who E-who O S-did-what O B-to I-to I-to E-to B-when E-when O
In this assignment, you will implement a model that performs shallow semantic parsing by predicting IOBES tags, with the help of the shallow syntactic parser you have built in part B.
The first step in scientific research is to observe the data. You are provided with a traindata.xml and a devdata.xml. They represent the training set and the development test set respectively.
Both training set and development set are in XML format, in which:
Here is an example:
<?xml version="1.0" encoding="UTF-8" ?>
<dataset>
<sent>
<frame>
<arg type="who">
<token>He</token>
</arg>
<pred>
<token>reckons</token>
</pred>
<arg type="to-whom">
<token>the</token>
<token>current</token>
<token>account</token>
<token>deficit</token>
<token>will</token>
<token>narrow</token>
<token>to</token>
<token>only</token>
<token>#</token>
<token>1.8</token>
<token>billion</token>
<token>in</token>
<token>September</token>
</arg>
<token>.</token>
</frame>
<frame>
<token>He</token>
<token>reckons</token>
<arg type="who">
<token>the</token>
<token>current</token>
<token>account</token>
<token>deficit</token>
</arg>
<token>will</token>
<pred>
<token>narrow</token>
</pred>
<token>to</token>
<arg type="to">
<token>only</token>
<token>#</token>
<token>1.8</token>
<token>billion</token>
</arg>
<arg type="when">
<token>in</token>
<token>September</token>
</arg>
<token>.</token>
</frame>
</sent>
</dataset>
As you can see, the data in not given in IOBES format. To make your life easier, we have already converted the dataset into IOBES format with this provided converter function string semantic_frames_to_iobes(const string &semantic_frame_xml);. traindata_part_c_iobes.xml and testdata_part_c_iobes.xml are the converted datasets, in which:
<?xml version="1.0" encoding="UTF-8" ?>
<dataset>
<sent>
<frame pred_position="1">
<token type="S-who">He</token>
<token type="O">reckons</token>
<token type="B-to-whom">the</token>
<token type="I-to-whom">current</token>
<token type="I-to-whom">account</token>
<token type="I-to-whom">deficit</token>
<token type="I-to-whom">will</token>
<token type="I-to-whom">narrow</token>
<token type="I-to-whom">to</token>
<token type="I-to-whom">only</token>
<token type="I-to-whom">#</token>
<token type="I-to-whom">1.8</token>
<token type="I-to-whom">billion</token>
<token type="I-to-whom">in</token>
<token type="E-to-whom">September</token>
<token type="O">.</token>
</frame>
<frame pred_position="7">
<token type="O">He</token>
<token type="O">reckons</token>
<token type="B-who">the</token>
<token type="I-who">current</token>
<token type="I-who">account</token>
<token type="E-who">deficit</token>
<token type="O">will</token>
<token type="O">narrow</token>
<token type="O">to</token>
<token type="B-to">only</token>
<token type="I-to">#</token>
<token type="I-to">1.8</token>
<token type="E-to">billion</token>
<token type="B-when">in</token>
<token type="E-when">September</token>
<token type="O">.</token>
</frame>
</sent>
</dataset>
Note that in the converted IOBES tags, the predicated is labeded as "O" instead of "S-did-what". This is because, the predicate position is part of the input to your classifier.
Find insightful patterns in the data. Good observations comes from statistical analysis. For example, here are some directions may be useful in finding patterns.
Report your observations about the data. You might use the hints we gave you but you are not limited to them.
According to the pattern you observed, please propose some shallow semantic parsing models. The next step is to compare those models theoretically, in the following aspects:
Write down your proposed hypotheses together with their pros and cons based on questions above.
Here you need to design experiments that validate/invalidate the hypotheses you came up with.
Write a detailed explanation for your each model indicating how are they reflecting their underlying hypothesis
Write your own C++ code to define your model.
Recall that when performing shallow semantic parsing, the first step is to locate predicates (did-what). Given that you have a good POS tagger and shallow syntactic parser, identifying predicate is not a difficult task. However, according to the CoNLL 2009 shared task specification, predicate identification is not part of the task. Since we are following the same evaluation rules as of CoNLL 2009 task, you don't need to write this predicate identification function as well. If you are interested in such a predicated identification function (even it's unrelated to the assignment), you can look at a naive implementation below:
/**
* judge if a token is a predicate
* in this assignment every predicate is a single token
* \param sentence the sentence where the token is in
* \param postags the POS tags of the sentence (predicted by your model)
* \param iobes_chunking_tags the chunking tags of the sentence
* (predicted by your shallow syntactic parser, in IOBES format)
* \param index the index of the token to judge
* \return whether the token is a predicate or not
*/
bool is_predicate(const vector<token_t> &sentence, const vector<symbol_t > &postags, const vector<symbol_t> &iobes_chunking_tags, unsigned index) {
// this starting code demonstrates a naive logic, which says "every verb is a predicate"
auto postag = postags[index];
return postag == "VB" || postag == "VBN" || postag == "VBZ" || postag == "VBG" || postag == "VBD" || postag == "VBP";
}
Build a feedforward network that reflects your hypothesis. The starting pack already contains a fully functioning 2-layer feedforward network as an example, that takes the current token, the predicate token, the POS tag of current token, shallow syntactic tag (in IOBES format) of the current token, and predicate-target distance as input:
/**
* create your custom classifier by combining transducers
* \param training_set the training set that your classifier will train on
* \param postag_vocab a list of all possible postags
* \param iobes_syntactic_tag_vocab a list of all possible syntactic chunk tags (with IOBES prefix), like "I-NP" "O-NP" etc.
* \param iobes_semantic_role_vocab a list of all possible semantic roles (with IOBES prefix), like "I-who" "O-who" etc.
* \return a classifier object
*/
transducer_t your_classifier(const vector <sentence_t> &training_set, const vector <symbol_t> &postag_vocab,
const vector <symbol_t> &iobes_syntactic_tag_vocab,
const vector <symbol_t> &iobes_semantic_role_vocab) {
// in this starting code, we demonstrates how to construct a 2-layer feedforward neural network
// that takes the target token, the predicate, the target token POS tag,
// the target token IOBES shallow syntactic tag, and target-predicate distance as input
// first you need to assemble the vocab you need
// in this simple model, the vocab is the set of all tokens that appear in training set
// we make use of std::unordered_set data structure to collect tokens, because it naturally removes duplicates
std::unordered_set<symbol_t> token_set;
for (const auto &sentence:training_set) {
for (const auto &token:sentence) {
token_set.insert(token);
}
}
vector <symbol_t> vocab(token_set.begin(), token_set.end());
// create an embedding lookup layer will convert token to tensor
auto embedding_lookup = make_embedding_lookup(64, vocab);
// create an 1-hot layer that is intended to handle the POS tag of current token as input
// the size of postag vocabulary are small, a 1-hot layer will work just fine
auto postag_onehot = make_onehot(postag_vocab);
// create an 1-hot layer that is intended to handle the IOBES shallow syntactic tag of current token as input
// the size of IOBES syntactic tag vocabulary are small, a 1-hot layer will work just fine
auto iobes_syntactic_onehot = make_onehot(iobes_syntactic_tag_vocab);
// this layer is intended to handle predicate-target distance.
// the distance comes as a scalar, this layer will convert it into a rank 1 tensor with dimension 1.
auto scalar_to_tensor = make_scalar_to_tensor();
auto concatenate = make_concatenate(5);
auto dense0 = make_dense_feedfwd(64, make_tanh());
auto dense1 = make_dense_feedfwd(iobes_semantic_role_vocab.size(), make_softmax());
auto onehot_inverse = make_onehot_inverse(iobes_semantic_role_vocab);
return compose(
group(
embedding_lookup, // handles the input - target token
embedding_lookup, // handles the input - predicate tokoen
postag_onehot, // handles the input - target token POS tag
iobes_syntactic_onehot, // handles the input - target token IOBES shallow syntactic tag
scalar_to_tensor), // handles the input - predicate-target distance
concatenate,
dense0, dense1, onehot_inverse);
}
The starting pack also contains an example on how to supply the current token, the predicate token, the POS tag of current token, shallow syntactic tag (in IOBES format) of the current token, and predicate-target distance as input.
You need to invoke your shallow syntactic parser. To make your life easier, we have invoked your shallow syntactic parser, and you can directly get the result as IOBES shallow syntactic tags, from the parameter iobes_chunking_tags.
/**
* TODO: fill in documentation for return
* besides the target token to SRL label, your model may also need other "context" input
* this function defines the inputs that your model expects
* \param sentence the sentence where the token is in
* \param postags the POS tags of the sentence (predicted by your model)
* \param shallow_syntactic_tags the shallow syntactic tags of the sentence
* (predicted by your shallow syntactic parser, in IOBES format)
* \param target_index the position of the target token to SRL label
* \param predicate_index the position of the predicate
* \return the list of features that your classifier expects
*/
vector<feature_t> get_features(const vector<token_t> &sentence, const vector<symbol_t> &postags,
const vector<symbol_t> &shallow_syntactic_tags, unsigned target_index,
unsigned predicate_index) {
// this starting code demonstrates how to define input as:
// the target token, the predicate, the target token POS tag, the target token IOBES shallow syntactic tag, and target-predicate distance
return vector<feature_t>{sentence[target_index], sentence[predicate_index], postags[target_index],
shallow_syntactic_tags[target_index],
(double) target_index - predicate_index};
}
After you have built one of your proposed models in assignment.cpp, you can run the command make and ./main to compile and run your model. You will get a part_c_prediction.xml, which contains your model prediction on the development test dataset, in exactly the same format as all other data files. Please observe your model output, find out which tokens your model failed to tag, and most importantly, explain why.
Besides outputting the part_c_prediction.xml, you will also get a F score of your model, following CoNLL 2009 shared task evaluation scheme. Here is how it works: for each semantic frame, we compute a precision and recall in such a way:
And then, an F score for each frame is computed as:
Where P means precision and R means recall.
Write down your model F score in the report.
Find out which test examples your model failed to classify, and why your model failed to classify them. If there are more than 4 failures, you only need to report 4.
After analyzing why your model went wrong, you should be able to make a better hypothesis. Now you have completed one iteration of scientific research. On the next iteration, you compare your new hypothesis theoretically and empirically again, doing more error analysis, and coming up with more awesome model.
Start another scientific method iteration.
May 10, 23:59
You need to submit assignment3_part_c.tgz archives via CASS, that only contains:
Note: If you want to update your model that you built in part B, you can re-submit to the part B checkpoint.